

Blog de Comunicación y Marketing Jurídicos

07 septiembre 2017
![]()
![]() Por Sara Molina
Por Sara Molina

 Una vez más parece que entender determinados términos anglosajones relacionados con la tecnología se nos hace cuesta arriba a los juristas. Pero en un mundo y en un sector donde la base está en los datos que manejamos me parecía importante ver qué implica y si se está haciendo algo en la actualidad en España respecto al denominado Machine Learning. Este artículo no pretende convertir al que lo lea en experto, pero por lo menos sí dotar de una base de conocimiento mínimo sobre lo implica y qué cambios puede traer al trabajo de un abogado.
Una vez más parece que entender determinados términos anglosajones relacionados con la tecnología se nos hace cuesta arriba a los juristas. Pero en un mundo y en un sector donde la base está en los datos que manejamos me parecía importante ver qué implica y si se está haciendo algo en la actualidad en España respecto al denominado Machine Learning. Este artículo no pretende convertir al que lo lea en experto, pero por lo menos sí dotar de una base de conocimiento mínimo sobre lo implica y qué cambios puede traer al trabajo de un abogado.
El Machine Learning es una rama de la inteligencia artificial aplicada (la denominada Weak AI) que trata de lograr que las máquinas aprendan de forma automática. Este modelo de aprendizaje automático está basado en el entrenamiento de algoritmos para que, a partir de patrones obtenidos del análisis de datos, realicen predicciones perfeccionando modelos que nos ayuden a generar ideas y tomar mejores decisiones. Por tanto, cuantos más datos haya disponibles para aprender y más rico y completo sea el algoritmo, funcionará mejor.
Los algoritmos de aprendizaje se suelen clasificar entre:
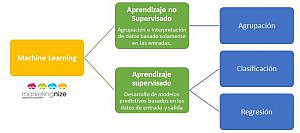
Por tanto, podemos decir que el Machine Learning está relacionado con el tratamiento de datos o Data Mining y la creación de modelos predictivos. No se trata de ciencia ficción, todos los días Google identifica nuestras preferencias y según ellas generan patrones y perfila nuestros gustos para ofrecernos aquello que cree que nos interesa. Además compañías como Amazon, Azure o IBM entre otras cuentan con plataformas muy potentes basadas en este aprendizaje automático.
El Machine Learning ha dado lugar en nuestro sector a diferentes proyectos de “Legaltech” que se basan en el uso de la tecnología y el software en los servicios legales. En este campo destaca el mapa vivo y los estudios realizados por Jorge Morell Ramos (@Jorge_Morell), jurista fundador del despacho especializado en nuevas tecnologías “Términos y Condiciones, cuyo “Legal LAB” presenta ya un área dedicada a “Legaltech”.
En el campo del Machine Learning en España destacan, a día de hoy, cinco iniciativas accesibles:
En el trabajo que hacemos los abogados, la información y su tratamiento es una de las tareas que nos llevan más tiempo, así que cuanto más rápido podamos hacerlo más tiempo podremos dedicar a desarrollar una estrategia eficaz para nuestros clientes. La digitalización de la información facilita este trabajo.
Aunque sin duda, hay una serie de problemas que impiden un mayor desarrollo del uso del análisis de datos. Por un lado, la información que las firmas de abogados están analizando pertenece a sus clientes, y necesita ser debidamente anonimizada antes del análisis y, por otro lado, que no existe el volumen suficiente de open data en España.
El ejercicio de la abogacía requiere habilidades cognitivas que están más allá del dominio del aprendizaje automático y la IA. Según un artículo publicado en “Washington Law Review” de Harry Surden, los abogados deben utilizar rutinariamente el razonamiento abstracto y habilidades para resolución de conflictos en entornos de incertidumbre jurídica. Los algoritmos usados actualmente en Inteligencia Artificial son incapaces de replicar la mayoría de las capacidades intelectuales en aspectos relacionados con el razonamiento analógico, que son fundamentales en el trabajo de un abogado.
En conclusión, actualmente y en un futuro cercano el Machine Learning no reemplazará el trabajo de un abogado, pero se trata de una herramienta que en líneas generales es útil a día de hoy para:
Sara Molina
TWITTER: @saramolinapt
WEB: Marketingnize
BLOG: http://marketingnize.com/blog/
COMUNIDAD ONLINE ABOGACÍA: www.abogacia.es/comunidad/saramolinapt/
Blog de Comunicación y Marketing Jurídicos
Planes de negocio, acciones promocionales, estrategia de comunicación, posicionamiento en el mercado ... información y herramientas útiles para que los nuevos abogados y los estudiantes de Derecho empiecen a familiarizarse con lo que, posiblemente, no les van a enseñar. AUTORES: David Muro, Donna Alcalá, EugeniaNavarro, Francisco Pérez Bes, Jaime Saz Fernández-Soto, Lidia Zommer, José Ramón Chaves, Marc Gericó, Óscar León, Rafael Guerra, Javier Lorente, Salvador Cortes, Berta Santos, Cristina M. Ruiz , Diego Alonso, José Luis Pérez Benítez, María Antonia Carmona, Rosa Manrubia .
1 abril, 2025 De la IA al abogado Rainmaker: lo que de verdad mueve el futuro de las firmas legales
20 marzo, 2025 Alianzas entre despachos: un enfoque bidireccional
11 marzo, 2025 Cómo hablar menos de nosotros mismos para empezar a cerrar clientes
25 febrero, 2025 La evolución de la industria legal: de la tradición a los agentes de IAgen
